

こんにちは~。
クロガネです。年単位ぶりの更新ですね。
今回は画像生成の記事です。
巷ではMidjourneyがだいぶ流行りました。一部の人には定着したともいえるかもしれません。
僕も課金している口です。

(こういうの生成できるのさいこ~)
さて、
こういう画像生成系に触れると気になってくるのが、
「他の類似サービスってないんかい?」
ってこと。
調べたらいくつもあります。
有名どころを挙げると
・DALL-E-2(ベータ版がアクセスできるようになって文字での画像生成ブーム?が広まった原因)
・DALL-E mini(↑の古い版をwebブラウザで楽しめる。ただ、アクセスが混雑して動い貸せないこともしばしば)
・Imagen(googleから出た奴。こっちはまだ触れない?)
・DiscoDiffusion(似たような感じのやつ)
・Crypko(二次元の立ち絵特化!ただまだ商用ライセンスが販売されてない)
など、結構あります。
個人的には、Midjourneyが流行った原因は、
「誰でも触れて、ライセンスが緩い」
というところにあると思います。
Midjourney側は、お金さえ払えば著作権は譲渡する、と主張しているので。
(厳密には著作権問題があります。以下などが参考になります。)
まあ、この辺の厳密なことはさておき、代替品を探してみました。
選定基準は同じく、
「使いやすくて、ライセンスが緩い」
です。
Stable diffusion
こいつもMidjourneyと同じく画像生成系です。
かなりきれいな画像が生成される、ということで話題になっていました。

(よく見本で生成される馬に乗った宇宙飛行士)
こういう、実写化と思うようなリアルな画像がものの数十秒で生成されます。
そういった意味で、一部界隈では注目されていました。
(もっと言うと、これも権利周りの問題を抱えています。
参考:まるで人間のアーティストが描いたような画像を生成するAIが「アーティストの権利を侵害している」と批判される – GIGAZINE)
さて、こいつは「DreamStudio」という名前のサービスでオンライン版が公開されています。
https://beta.dreamstudio.ai/ただ、こちらは有料。ならMidjourneyのままでもよくね?となるので見送りします。
それで見つかったのが、「Stable diffusion」のColab Notebook版です。
Colab Notebook版
Colab Notebook版がありましたので、使い方を説明していきます。
これはHugging FaceからモデルをDLして使います。
なので、使用するまでのステップは、
1.Google Colaboratoryでノートブックを開く
2.HuggingFaceへの会員登録&トークン生成
3.画像生成
の3段階で生成出来ます。
また、Colab Notebookの無料版を使用すれば、実質無料で画像生成出来ます。
それでは触っていきましょう。
1.Google Colaboratoryでノートブックを開く
こちらのリンクから使用できるはずです。
Stable Diffusion with 🧨 diffusers – Colaboratory (google.com)
開いたら、まずは「ドライブにコピー」をクリックします。自分のGoogleドライブにこのノートブックの複製が保存されます。
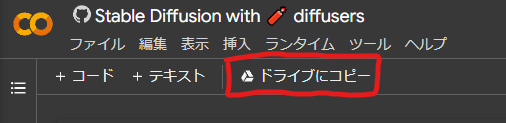
そしたら、まずは、初期設定。
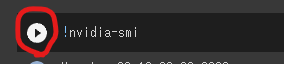
このように再生マークがついてるボタンを、上から順に押していきます。
注意点はこの部分。
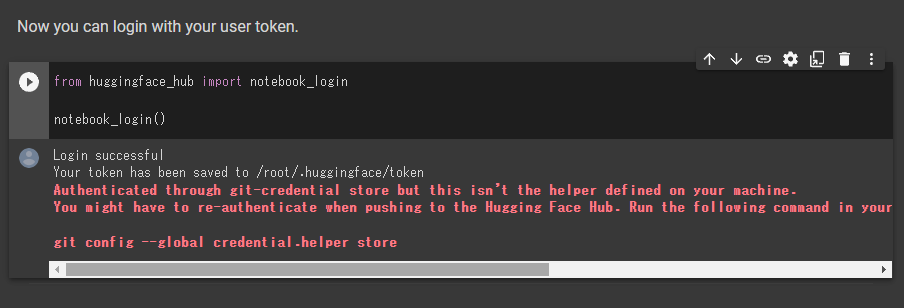
HuggingFaceへのログインが必要になります。
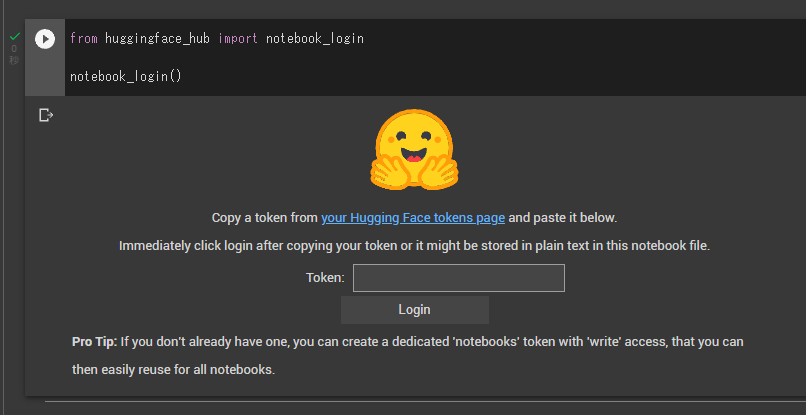
実行すると、以下のようにトークンが要求されます。
2.HuggingFaceへの会員登録&トークン生成
なので、まずはHuggingFaceの会員登録ページに飛びます。
https://huggingface.co/join
メールアドレスとパスワードを設定して、

ユーザー名、名前を登録して会員登録します。

すると、認証メールが届き、リンクを踏むことでトークンを生成出来るようになります。
次に、https://huggingface.co/settings/tokens に飛び、トークンを生成します。
リンクを開くと、「new token」というボタンがあるので押します。
押すと、トークン名を設定します。任意の文字列を設定しましょう。
「Generate a token」を押すとこのようにトークンが生成されます。
※注意!トークンはログイン情報なので、他者にバレるとこちらの名義で好き放題されます!

コピーのボタンを押して、先ほどまで開いていたノートブックに戻り、tokenを入力し、ログインボタンを押します。
stable diffusionのモデルの利用にはライセンスへの同意が必要です。
なので、ノートブックからHuggingFaceのモデル配布のページを開く必要があります。
https://huggingface.co/CompVis/stable-diffusion-v1-4
上記リンクを押すと、ライセンスの概要と同意が求められます。
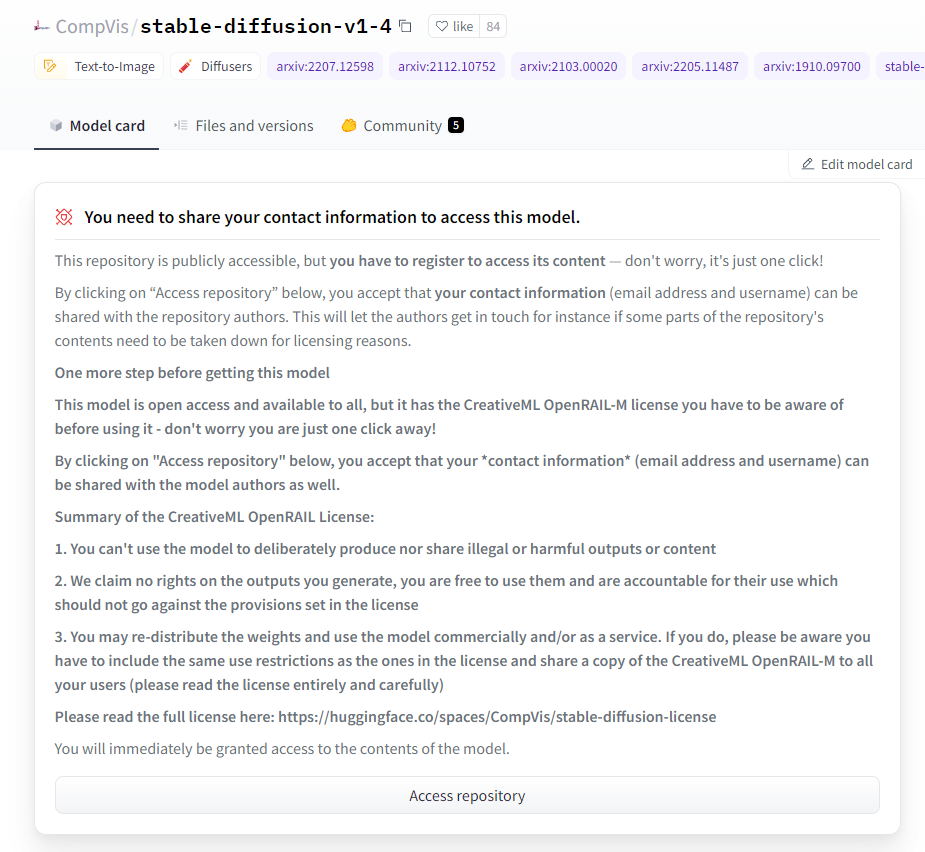
(画像はシークレットモードでの表示)
ライセンスは「CreativeML OpenRAIL License」という特殊なもの。
割と自由に利用できるのかな?
DeepLで翻訳するとこんな感じ。
=========このリポジトリは一般に公開されていますが、コンテンツにアクセスするには登録が必要です。心配しないでください。下の「リポジトリにアクセス」をクリックすると、あなたの連絡先(メールアドレスとユーザー名)がリポジトリの作者と共有されることに同意したことになります。これにより、例えばライセンス上の理由でリポジトリのコンテンツの一部を削除する必要がある場合、作者は連絡を取ることができます。このモデルを入手する前にもう一歩このモデルはオープンアクセスで誰でも利用できますが、CreativeML OpenRAIL-Mライセンスがありますので、利用する前に知っておく必要があります - 心配しないでください。下の「リポジトリにアクセス」をクリックすると、あなたの*連絡先*(メールアドレスとユーザー名)がモデルの作者とも共有されることに同意したことになります。CreativeML OpenRAIL Licenseの概要。1. あなたは、違法または有害な出力やコンテンツを意図的に作成したり、共有するためにモデルを使用することはできません。2. 私たちは、あなたが生成した出力に対していかなる権利も主張しません。あなたはそれらを自由に使用することができ、ライセンスで設定された規定に反してはならないその使用について説明責任を負う。3. あなたは、重みを再配布し、モデルを商業的および/またはサービスとして使用することができます。その場合、ライセンスにあるものと同じ使用制限を含め、CreativeML OpenRAIL-Mのコピーをあなたのすべてのユーザーに共有しなければならないことに注意してください(ライセンスを完全にかつ注意深く読んでください)。ライセンスの全文はこちらでご覧ください: https://huggingface.co/spaces/CompVis/stable-diffusion-license
=======
CompVis/stable-diffusion-v1-4 · Hugging Face より
あとはノートブックに戻り、引き続き、再生ボタンを押していきます。
3.画像生成
ここまで進めると、画像生成することが出来る状態になります。
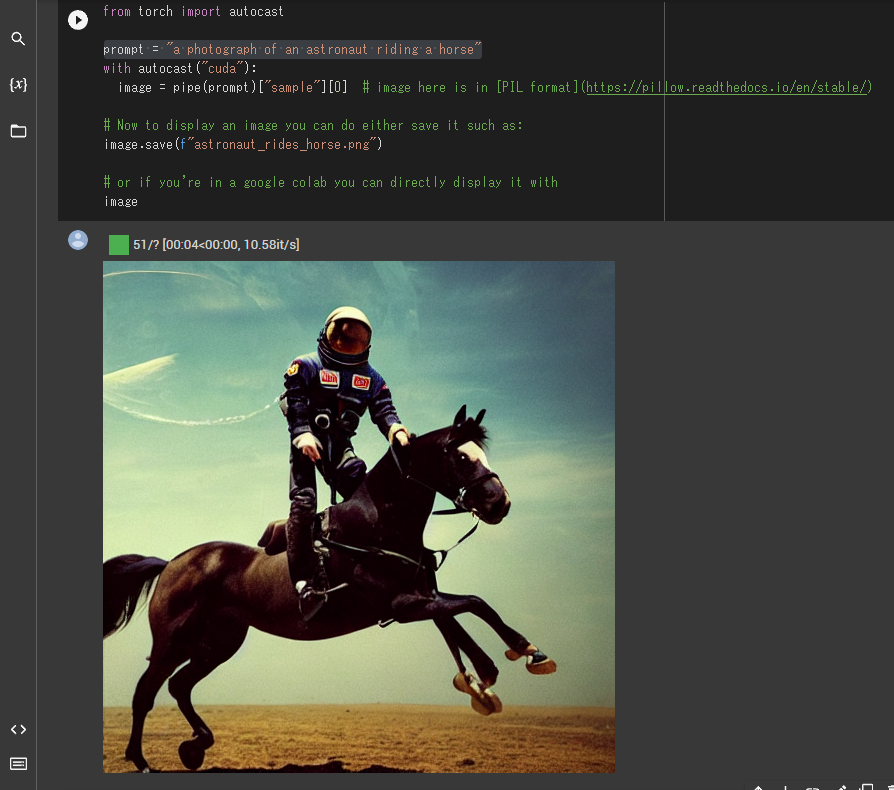
今までの多くの画像生成系と異なり、colabの使用上限を上回るまでは無料で使えます。まずは再生ボタンを押して生成してみましょう。
僕の環境&執筆時では、ものの15秒程度で生成されました!
わーいぱちぱち
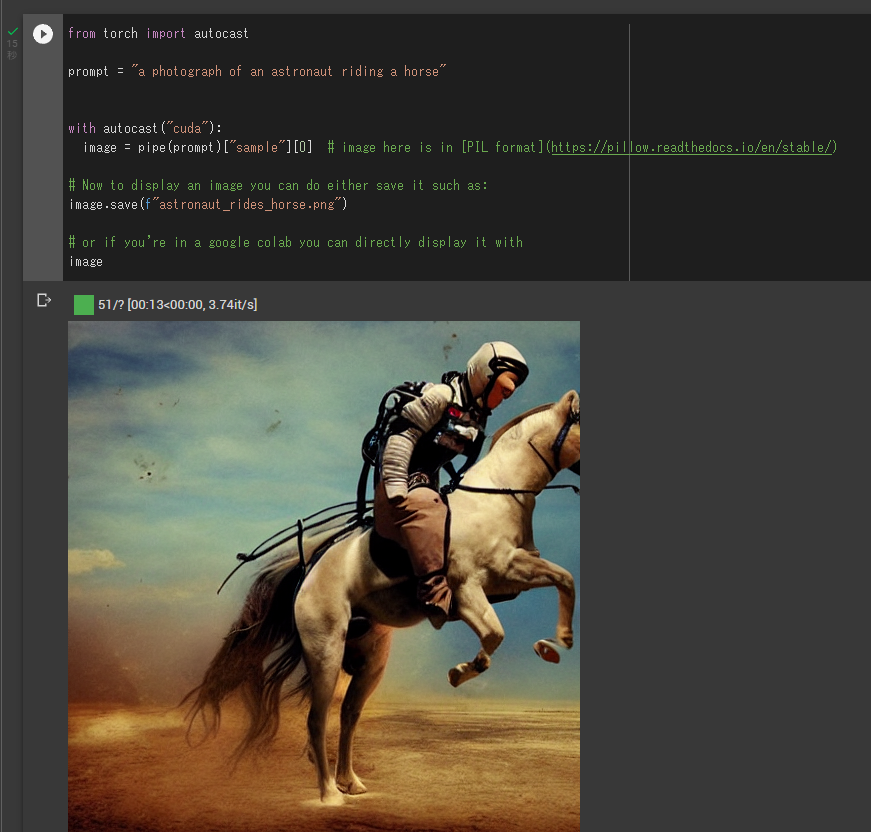
今回みたいに若干破たんしている画像が生成されることがしばしばあります。
が、無料で回せてすぐ生成されるので何度も試すことが出来ます。
色々試す。生成時の設定など。
さて、このノートブックには親切にもパラメーター一覧や他の生成の仕方も乗っています。
試しておきたいのは以下。

画像サイズとステップ数です。
コードに書き足して設定して上げます。
デフォルトの変数は以下。

解像度
heightとwidthはそのまま解像度です。
256の倍数の解像度のみ設定できる?(要検証)
ただし、無料版のcolabのスペック上、1024*512まで位が限界でした。
勿論、解像度を高めると生成まで時間がかかります。
恐らくですが、一度誤った解像度設定をすると、メモリ上に設定が残りGPUのメモリがあふれるようです?(要検証)
解像度の変更は後述の「ランタイムを再起動」をやっておいた方が無難です。
参考までに、キーワードをデフォルトの「a photograph of an astronaut riding a horse」にしたまま、解像度を変更したときにかかった時間をリストにしておきます。面倒なので1回の生成分のみメモ。step数は50。
| 解像度 | 生成にかかった時間 |
| 1024*512 | 41.171秒 |
| 512*512 | 15.262秒 |
| 256*256 | 4.232秒 |
256*256はまともな画像が生成されないのと、1024*512は縦に融合したような画像が生成されがちなので、デフォルトの512*512でステップ数をいじる方が無難かと。
ステップ数
ステップ数は値を大きくすることで生成にまで時間がかかります。代わりに絵が綺麗になります。
デフォルトは50ステップで、ステップ数を増やすと、体感、増やしただけ遅くなります。
(100にしたら倍かかる感じ。)
ステップ数はGPUのメモリにはほぼ影響なし?
参考までにステップ数での見た目の変化を乗せておきました。
解像度は512*512。
テキストを試行錯誤して雰囲気を確かめるだけなら、25でも十分かも?
(シード値が違うので運が良かっただけかもしれませんが)
描かれているものの正確性はともかく、100くらいだとかなり細かく描画されてますね。
実用的なのは25で生成しまくって、本番は100以上に設定かな?
500まで行くとあまり違いを感じられませんね。
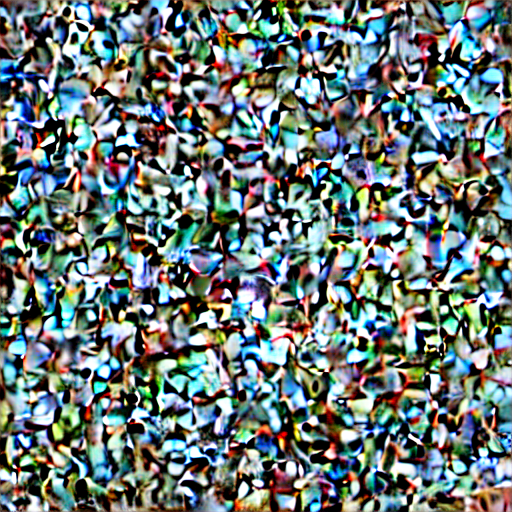
num_inference_steps=10
(5.583秒)
num_inference_steps=15
(6.33秒)
num_inference_steps=20
(7.401秒)
num_inference_steps=25
(8.594秒)
num_inference_steps=35
(11.778秒)
num_inference_steps=50
(15.158秒)
num_inference_steps=100
(28.721秒)
num_inference_steps=500
(40秒くらいだったきがする)
まとめて生成
少し下の所に、グリッドで複数画像をまとめて生成する、というものがあります。

「from PIL import Image」から始まるコードを実行してから実行できます。
3枚のグリッド、もしくは3*4枚のグリッド、どちらでも生成出来ます。
少しだけ生成が遅くなりますが、3枚のグリッドの方は512*512の100ステップで81秒くらいで生成出来たときもありました。枚数分、生成時間が増えているだけです。
呪文がおおよそ決まって、一気に生成して選別するにはこちらがおすすめ。放置しておけばいいので。
(ただし画像は1枚にまとめてあるので使う時は自分で切り分けましょう)
GPUメモリがなくなる→ランタイムを再起動しよう
いろいろ触っているとGPUメモリがオーバーすることがあります。
一度、大きすぎる解像度を設定するとメモリに乗ったままになってしまうようです。
その時はランタイムを再起動してあげましょう。
その時は「ランタイム」→「ランタイムを再起動」を実行してあげましょう。
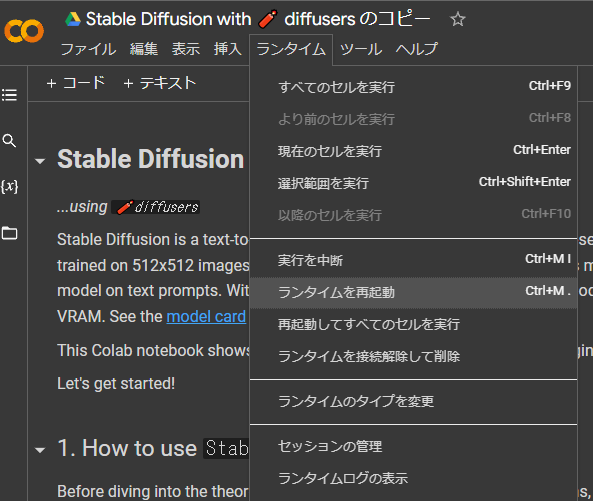
ただし、すべてリセットされるため、すべての手順を最初からやってあげる必要があります。
(念のため、トークンは使いまわせるので再生成は必要ありません。)
NSFWフィルターについて
さて、本記事では手元で何でも生成できてスゲー、って感じの記事にしたいのですが、一つだけ弱点があります。
それはNSFWフィルターです。端的に言うとエログロ除去です。
生成後、画像がエログロフィルターに引っかかるかを判定して、それを除去するというものです。
ただ、健全な画像も大量にNSFW判定されるガバガバ仕様なので、この辺が残念ポイント。
柴犬の生成でも体感1/4はNSFW判定を食らいました。実際に柴犬で生成した場合でも普通に除去されます。
これはwebアプリ版や、この先出る「DreamStudio」版でも発生するしっかりと面倒な問題です。画像が生成されないにも関わらず、1回分の生成コストや時間が浪費されるという欠点があります。
実はcolab版では回避策があります。ググると出てきます。
が、その前に、そもそもなぜそんなものが実装されているか、という問題があります。
普通にこのフィルターが無いと問題があるからです。所謂、ディープフェイクというものです。余裕で作れます。ライセンス的には試しに生成するのもアウトです。
どうしても常に生成したい場合はライセンスを熟読した上で、ググって自分で追加して下さい。普通に出てきます。
捏造出来ちゃうよねって話。
流れ的にフェイクニュースへの危険性にも言及しておきましょう。ということで試しにヤバいモノを作ります。

文具屋で働くザッカーバーグ。雑貨バーグってなwwwww
はい。
こんな感じで実在する人物が絶対にしていないことをさせた画像を生成することが出来ます。なので、学習させられるくらい有名な人物のフェイク画像がいくらでも生成出来ます。
フェイクニュースは良くないね!
少し前に話題になったGPT-3とかと組み合わせればまるで本当にあったかのような記事を作ることが出来ます。良くないね!
おわりに
現状まとめれる範囲はこんな感じでした。
Midjourneyと同じく、呪文周りの云々があるとおもうので、また何か生成出来たら次の記事を出そうと思います。
さいごにまた柴犬ガチャして終わります。



さいこ~
それでは。
(追記)webアプリ版について
webアプリ版ありました。
Stable Diffusion – a Hugging Face Space by stabilityai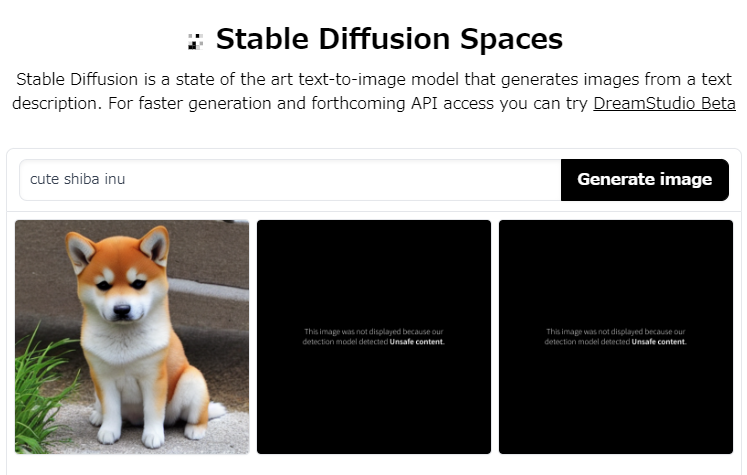
こちらは簡単。開いて入力して放置で終わりです。
ただ、圧倒的に遅い。待機だけで350秒ほどかかりました(執筆当時)。
その待ち時間でここまでの操作が出来てしまうので、colab版の方が圧倒的におすすめです。
一度トークンを作成できていれば、大体150秒くらいで画像生成までたどり着けます。今までの結果の通り、余った時間で7枚くらい生成出来ます。普通に便利です。