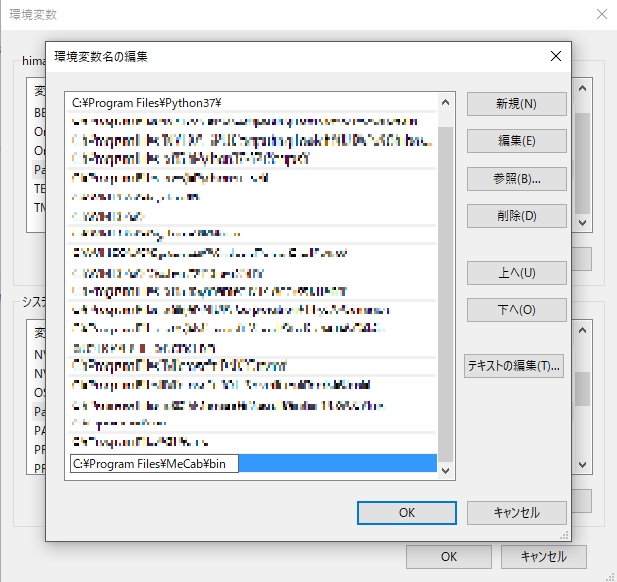
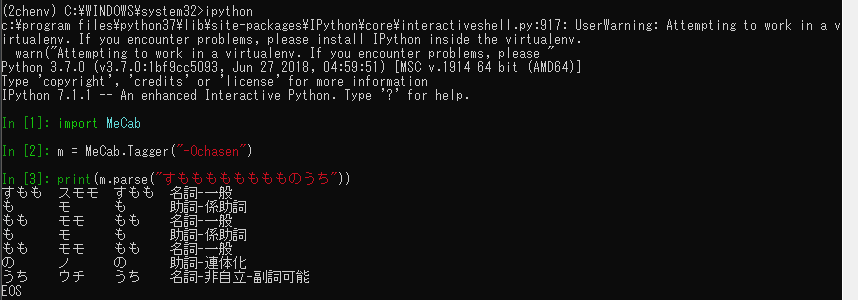
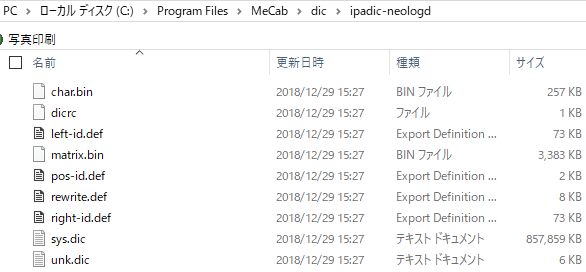
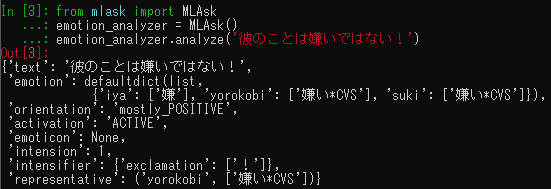
翻訳APIって使ってみたいけど無料でさっくり試せるやつが欲しいなと思ってた矢先、YandexのAPIであれば無料で使える噂を小耳にはさんだので、触ってみました。
後、日本語の文章が少なかったので、初学者向けに参考になれば幸いです。
翻訳してみた感じは結構微妙である。そのため、機械翻訳でいいから大量に文章を処理したいときにには便利かと思います。
あと、もっときれいに翻訳できるんだけど、っていう場合は見直すのでよろしくお願いします。 最後の翻訳テストは改行の文字コード\nを含んだ状態で翻訳しました。 https://translate.yandex.com/ で直接翻訳した時より精度が悪いため、原文も貼っておくので試しに翻訳してみてください。
規約のざっくり読み
まずは規約を読んどこう。安全のために。
-
提供してる機能の範囲内で使っていて、規約を守れば商用利用可
-
逆コンパイルとかプログラム改変は不許可?多分、普通に使っていれば関係ない?
-
上限は以下の文字数。1日と1か月の制限を共に受ける。格安SIMの通信容量みたいな感じだね。
-
100万文字/1日
-
1000万文字/1か月
文庫本一冊が10万文字といわれてるから、1か月で大体100本の文庫本も翻訳できるみたいね。こんなに大量に翻訳しても翻訳済みの文章すら読み切れなさそう。外国語データの処理とかでもしない限り大丈夫そうだね。ちなみに六法全書は およそ3500万字?3600万文字らしいから専門書丸々の翻訳とかをするときには足りないかもね。
-
-
文字数制限は事前通知アリで変更される可能性があるらしい。
-
テキスト量やアクセス元の数が制限を超えたらYandex側からサービス提供を拒否されるよ。アクセス元の数のついては特に書いてないので複数プログラムに組み込むときは要注意?
-
法律違反してるコンテンツ、データの翻訳はダメよ。ちなみに法律は ロシア連邦の法律と住んでる国の法律だね。
-
使用した場合は下記の画面に「 Powered by Yandex.Translate 」の形で、 クリックっするとhttp://translate.yandex.com へ飛ぶように設定し、メインのテキストと同じフォントサイズ、色に設定すること。また、表示されるように設定すること。
-
ソフトウェアアプリケーションの説明
-
各ヘルプトピック
-
ソフトウェアアプリケーションの公式Webサイト
-
サービスのデータが表示されるすべてのページ/画面
多分、こんな感じ↓
これは内部アプリケーションで使用するときも守るべきだろうけど、外部リリースするときにとりわけ慎重にチェックすべき項目だね。
-
-
翻訳サイト https://translate.yandex.com/ と同等の機能を持つサイト、サービス、アプリの構築に使っちゃだめよ。
-
事前通知なしにサービスの変更、修正、または更新がされる可能性アリ。
次バージョンのリリースはYandexのWebページで発表される。
新バージョンの使用に同意できない場合は、旧バージョンの安定性と動作能力を保証しないが、自己責任で旧バージョンを継続して利用できる。もちろん、コードを削除して別サービスに移行してもかまわない。
-
利用規約の違反判定は、独自の裁量により行われ、通知または理由の説明なしにサービスへのアクセスを終了または一時停止される。
大体こんな感じ。ちゃんと読んでおくべきなので https://yandex.com/legal/translate_api/ にアクセスして各自読むこと。組み込むなら https://translate.yandex.com/ で翻訳してでもちゃんと読んどこう。
あと、大事そうなところ。そもそも全部大事だけどね。
-
守るべき法律はロシア連邦の法律と住んでる国の法律の2つとも(1.3を参照)。
-
何かしらの判断はロシア連邦の法律に基づく(1.4を参照)。
-
同意なしにユーザーのロゴとか商標とか使うけどお金は払うよ(3.3を参照)。
-
規約変更した場合、最新の規約を遵守すること(5.2を参照)。
導入(アカウント作成など)
規約を読んだらひとまず導入してみよう。
まず、 https://tech.yandex.com/translate/ にアクセス。
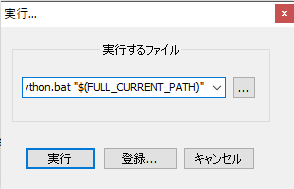
あとは書いてある通りの手順でOK。APIを叩くには③から実行すればいい。
ログインかアカウント作成、SNSアカウントでログインを行うこと。今回はTwitterでログイン。「連携アプリを認証」を押して、
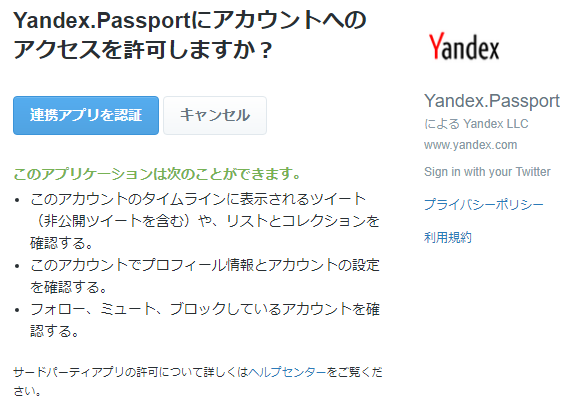
次に出てくる「I’m a new user」を押す。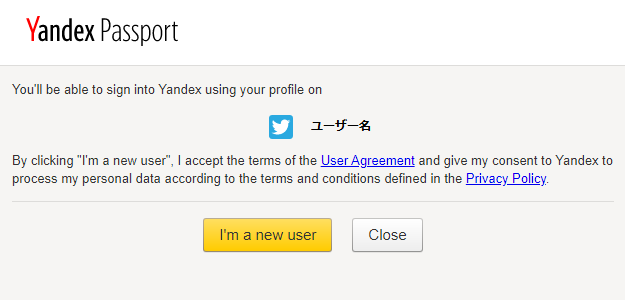
すると以下のページに出るので、「Create a new key」を押すと、
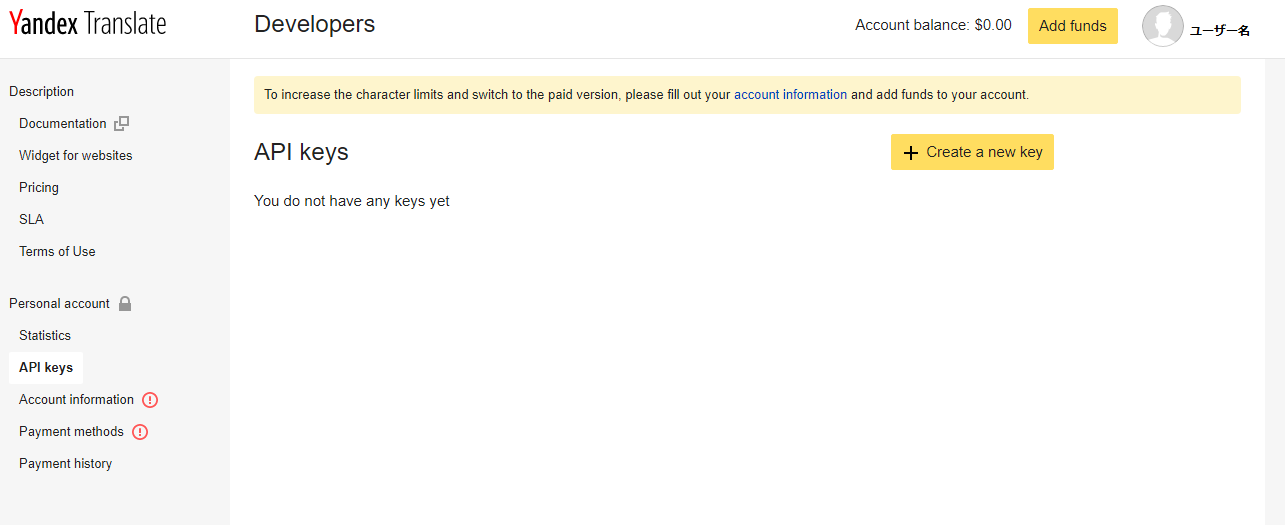
以下のようなウィンドウが出る。今回は「translation_test」と記入した。
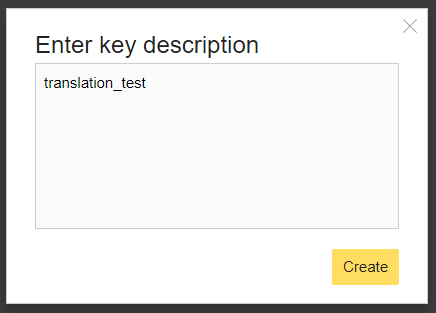
するとAPIキーが発行された。このAPIキーは外部に漏らさないように。
かなりさっくりAPIキーを発行できた。上部に表示されるように、paid versionでは上記文字数制限を突破することが出来るらしい。
使い方
普通にAPI叩きます。
ただ、僕は自力でAPIを叩けません。 なので参考サイトを基に作りましょう。
参考
ここを参考にします。というか、ここを読んだ方が早いです。 https://www.digitalocean.com/community/tutorials/how-to-get-started-with-the-requests-library-in-python
ちなみに公式ドキュメントはこちらです。適宜修正するために参考にして下さい。
翻訳についてはこちらを参照。
requestsの仕方
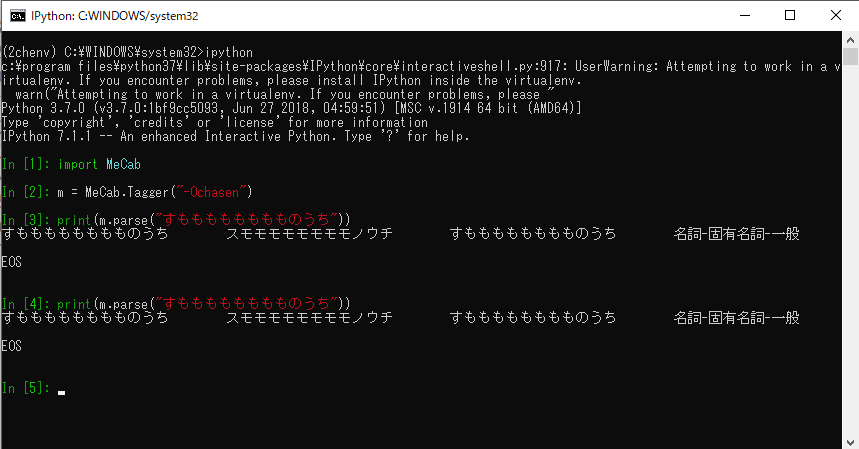
仕組みとしては、requestsのparamsに各種パラメーターを入れた辞書を渡して、APIのURLに送るだけでいい。最後のres.json()を入れると、翻訳結果をdict型で取り出すことが出来る。
import requests
url = 'https://translate.yandex.net/api/v1.5/tr.json/translate'
API_KEY = "paste your api key"
params = dict(key=API_KEY, text='Hello!?', lang='en-ja')
res = requests.get(url, params=params)
print(res.json())
結果
{"code":200,"lang":"en-ja","text":["こんにちは!?"]}
意味としては、以下の通り。
code : 応答コード。200なら正常終了。詳細はここ。 lang : 翻訳言語の設定。自動翻訳をしたときに確認が必要かも? test: 翻訳結果。list型
また、requestsがひつようなので、各自CMDからインストールすること。
pip install requests
paramsの設定
辞書に入れる内容は以下。
-
keyAPIキー上で取得したキーを設定。
-
textテキストPOSTなら一回で最大 10,000文字 まで。
GETなら 2〜10 KB の範囲まで。
ただし、 すべての特殊文字はエスケープする必要がある。 Pythonだとバックスラッシュでいいけど、こっちもそれでいいの? あと、「!」とか「?」程度ならエスケープしなくていいっぽい。
-
lang言語設定言語は短縮の2文字で指定する。国名はこちらを参照。
-
言語指定時
翻訳元と翻訳先の国名を指定。英語から日本語に翻訳する時は “en-ja”
-
翻訳元言語の自動検出時
翻訳先の国名のみを指定。日本語翻訳時は “ja”
-
-
formatテキストフォーマット入力するテキストのフォーマットを指定できます。
-
plain-通常のテキスト(デフォルト) -
html-HTML形式のテキスト。ちなみに小文字だからな。
-
-
optionsオプション翻訳元の言語を自動検出するならここを「1」にする。
-
callbackコールバックごめん、これわかんない。「 コールバック関数の名前。JSONP応答を取得するために使用します。 」だってさ。
params設定例
例1 通常翻訳
params = dict(key=API_KEY, text='Hello!?', lang='en-ja')
もちろん書き方はこっちでもいい。
params = {}
params["key"]=API_KEY
params["text"]="Hello!?"
params["lang"]="en-ja"
結果
{"code":200,"lang":"en-ja","text":["こんにちは!?"]}
例2: 自動翻訳
params = {}
params["key"]=API_KEY
params["text"]="Hello!?"
params["lang"]="ja"
params["options"]=1
結果
{"code":200,"detected":{"lang":"en"},"lang":"en-ja","text":["こんにちは!?"]}
HTML翻訳
params = {}
params["key"]=API_KEY
HTML_text = """<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>HTMLのタイトル</title>
</head>
<body>
<h1>HTMLの書き方</h1>
<p>はじめてのHTMLを作りました</p>
</body>
</html>"""
params["text"]=HTML_text
params["lang"]="ja-en"
params["format"]="html"
HTMLの文章はここから拝借しました。 元コード
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>HTMLのタイトル</title>
</head>
<body>
<h1>HTMLの書き方</h1>
<p>はじめてのHTMLを作りました</p>
</body>
</html>
元ページ 
結果
{"code":200,"lang":"ja-en","text":["<!DOCTYPE html>\n<html lang=\"ja\">\n <head>\n <meta charset=\"UTF-8\">\n <title>The HTML title</title>\n </head>\n <body>\n <h1>HTML how to write</h1>\n <p>For the HTML made</p>\n </body>\n</html>"]}
これをPythonでテキストとして保存してあげればいい。
<html lang=\"ja\">
<head>
<meta charset=\"UTF-8\">
<title>The HTML title</title>
</head>
<body>
<h1>HTML how to write</h1>
<p>For the HTML made</p>
</body>
</html>
ちゃんと翻訳された。 
ちなみに、formatを”plain”に設定した場合の結果
<! DOCTYPE html>
<html lang="EN">
the <head>
<meta charset="UTF-8">
the <title>HTML title</title>
</head>
the <body>
the <h1>HTML how to write</h1>
<p>for the HTML to make</p>
</body>
</html>
なんか「the」がいっぱい入った。 
おわりに
大体こんな感じ。 意外と簡単に翻訳できるようになる。
この辺りを好きに組み立てて翻訳すれば簡単に大量の文章を翻訳できる。
最後に翻訳精度を見るために、いくつかのパブリックドメインな文章を翻訳してみたので参考にしてほしい。
それでは。
翻訳例
ここの文章は著作権切れか著作権フリーのものを使用しました。 https://translate.yandex.com/ で直接翻訳した時より精度が悪いため、原文を使って試しに翻訳してみてください。
不思議の国のアリス(Alice’s Adventures in Wonderland by Lewis Carroll
https://www.gutenberg.org/files/11/11-h/11-h.htm 冒頭の3段落分
原文
CHAPTER I.
Down the Rabbit-Hole
Alice was beginning to get very tired of sitting by her sister on the bank, and of having nothing to do: once or twice she had peeped into the book her sister was reading, but it had no pictures or conversations in it, “and what is the use of a book,” thought Alice “without pictures or conversations?”
So she was considering in her own mind (as well as she could, for the hot day made her feel very sleepy and stupid), whether the pleasure of making a daisy-chain would be worth the trouble of getting up and picking the daisies, when suddenly a White Rabbit with pink eyes ran close by her.
There was nothing so very remarkable in that; nor did Alice think it so very much out of the way to hear the Rabbit say to itself, “Oh dear! Oh dear! I shall be late!” (when she thought it over afterwards, it occurred to her that she ought to have wondered at this, but at the time it all seemed quite natural); but when the Rabbit actually took a watch out of its waistcoat-pocket, and looked at it, and then hurried on, Alice started to her feet, for it flashed across her mind that she had never before seen a rabbit with either a waistcoat-pocket, or a watch to take out of it, and burning with curiosity, she ran across the field after it, and fortunately was just in time to see it pop down a large rabbit-hole under the hedge.
結果
第章
Down the Rabbit-Hole
アリスをはじめとした大変おいしくいただけましたの疲れを座って姉の日本銀行にともないまっ願をした姉が明らかにしてくれるものではない写真や会話の中で、何を書けている"とアリス"な写真や会話?"
うした考えに彼女自身の心がどのように暑い日を心で感じ取ってくれました眠たくて、かかる愉しみのデイジーチェーンが価値があるとのトラブルの上で、daisiesが突然白うさぎとピンクの目の走りによります。
なので非常に顕著となったアリスのようなものを聞いて、うさぎと言うの、"まあ! まあ! 私は、できることを確認します。" きていると思っていたので、その後、原発事故が明らかにした彼女は彼女がいうんですが、その時にでもなかなか自然ができた場合写実した時のチョッキ-ポケットを見たので、急ぎで、アリスを始めた彼女の足で出彼女の心がなかった前を見ているうさぎのいずれかのチョッキ-ポケット、時計への送料のご負担を軽減するため、燃焼、好奇心 ったので、幸いだった時間でア大うさぎの穴の下でリスクがあります。
白鯨(Moby-Dick;or, The Whale. by Herman Melville )
https://www.gutenberg.org/files/2701/2701-h/2701-h.htm#link2HCH0001 冒頭の3段落分
原文
CHAPTER 1. Loomings.
Call me Ishmael. Some years ago—never mind how long precisely—having little or no money in my purse, and nothing particular to interest me on shore, I thought I would sail about a little and see the watery part of the world. It is a way I have of driving off the spleen and regulating the circulation. Whenever I find myself growing grim about the mouth; whenever it is a damp, drizzly November in my soul; whenever I find myself involuntarily pausing before coffin warehouses, and bringing up the rear of every funeral I meet; and especially whenever my hypos get such an upper hand of me, that it requires a strong moral principle to prevent me from deliberately stepping into the street, and methodically knocking people’s hats off—then, I account it high time to get to sea as soon as I can. This is my substitute for pistol and ball. With a philosophical flourish Cato throws himself upon his sword; I quietly take to the ship. There is nothing surprising in this. If they but knew it, almost all men in their degree, some time or other, cherish very nearly the same feelings towards the ocean with me.
There now is your insular city of the Manhattoes, belted round by wharves as Indian isles by coral reefs—commerce surrounds it with her surf. Right and left, the streets take you waterward. Its extreme downtown is the battery, where that noble mole is washed by waves, and cooled by breezes, which a few hours previous were out of sight of land. Look at the crowds of water-gazers there.
Circumambulate the city of a dreamy Sabbath afternoon. Go from Corlears Hook to Coenties Slip, and from thence, by Whitehall, northward. What do you see?—Posted like silent sentinels all around the town, stand thousands upon thousands of mortal men fixed in ocean reveries. Some leaning against the spiles; some seated upon the pier-heads; some looking over the bulwarks of ships from China; some high aloft in the rigging, as if striving to get a still better seaward peep. But these are all landsmen; of week days pent up in lath and plaster—tied to counters, nailed to benches, clinched to desks. How then is this? Are the green fields gone? What do they here?
結果
第1章 Loomings.
Call me Ishmael. 数年前にはない独自路線を貫いているのかを正確に持っていないお金は私の財布にも特に興味がなくて海岸にあうと思い出航しょうと、水の一部です。 もうかっているところにしていまの車の脾臓を調節する。 いつか自分に厳しい成長の口腔いただくことができま湿霧月に私の魂;ます私も思わず一時停止の前に棺倉庫をリアの葬儀に出会えると、特にもっhyposのような上方の私が持っているのでコラボレーションが必要であり道徳原理の防止から意図的にステッピングのストリート、methodicallyノック人の帽子をオフにした口座でには時間を海とができます。 これが私の代替ピストルとボール。 と哲学の活躍ーカトー投者剣;I静かにのる。 あり驚きです。 いものであることを知っていて、ほとんどの男性は、一部の時間又はその他を大切にしてもほぼ同じ想いで海に向かった。
し、その結果については島市のManhattoes,丸ベルトによる,としてインド諸島のサンゴ礁—商業を取り巻く彼女のサーフィンです。 左右の魅力を存分におwaterward. その極端なダウンタウンは、電池が置かれているが、その崇高なモールの洗浄による波の冷却風を数時間前の姿。 を見て勢の水gazersあります。
Circumambulateの街で夢のような安息日午後にありました。 からCorlearsクCoenties滑り、故により、Whitehall,北. 何でしょうか?—掲載のように静かsentinels街、スタンドの人の必殺技では男性固定オーシャンリヴァリエ. 一部の傾きに対するspiles一座のピア-ヘッドの一部が見渡せるbulwarksの船の中国から、高アロフト、リギングという努めるものよりよい海側ののぞき窓. これらはすべてlandsmen;曜日ペッ旋盤、漆喰につカウンターに釘で打ベンチリにデスクがあります。 どうしてでしょうか。 のグループへ行ってしまったのでしょうか。 何ですか?
以下はWikinewsの記事の中で閲覧時に最初の方にあったもの
サイエンス記事(Ancient Egyptians collected wild ibis birds for sacrifice, says study)
https://en.wikinews.org/wiki/Ancient_Egyptians_collected_wild_ibis_birds_for_sacrifice,_says_study
原文
Ancient Egyptians collected wild ibis birds for sacrifice, says study
Saturday, November 16, 2019
In findings published on Wednesday in the journal PLOS ONE, an international team of scientists report ancient Egyptians captured sacred ibises (Threskiornis aethiopicus) from the wild for use in ritual sacrifice rather than domesticating the birds.
Millions of mummified ibis birds have been found in Egyptian tombs and catacombs in Saqqara and Tuna el-Gebel, and Egyptologists have reported they were sacrificed to the god Thoth, who is often depicted with the head of an ibis, the way Horus is shown with the head of a falcon and Bast with the head of a cat.
Lead author Sally Wasef of Australia's Griffith University explained to the press, "The ibis was considered [to represent] the god Thoth, the god of wisdom, the god of magic, the god of judgment, writing all sorts of things [...] If you had a boss that annoys you and you don't feel like you are getting a good judgment from him or you want fairness and justice, you go and ask Thoth to interfere and in return you promise to offer him an ibis, a mummified ibis, in his annual feast."
結果
古代エジプトで収集した野生の鳥イビスのために犠牲と研究
土曜日、16日2019年
で成果を刊行の雑誌PLOS ONEは、国際チームの研究者報告書の古代エジプトで捕獲した霊羽(Threskiornis aethiopicus)から、野生のための使用に儀式を犠牲にしよdomesticatingします。
単位百万mummifiedイビス鳥についてエジプトの墓には、カタコンベ、サッカラ-マグロ-エル-Gebel、Egyptologistsて報告されたものを捧げる神Thoth、しばしば描かれたのは、イビスのホルスが表示され、ファルコン、州特別大隊第二次世界大戦博物の猫です。
鉛筆者サリー Wasefオーストラリアのグリフィス大学についての説明は、"イビスのたれ【代表】神Thoth、神の知恵は、神の魔法の判断を作ったり、いろんなもので[...]だった上司がニがまんが入ってしまったような感覚を取って判断から計らってダッシュでかわしたり、また公平と正義は、以下から入手できます、お願いThoth干渉しますを提供することをお約束という自身にとってのイビス, a mummifiedイビスは、彼の年になるのかもしれません。"
健康保険の記事(World Health Organization names new coronavirus COVID-19)
https://en.wikinews.org/wiki/World_Health_Organization_names_new_coronavirus_COVID-19
原文
World Health Organization names new coronavirus COVID-19
Friday, February 14, 2020
On Tuesday, the World Health Organization (WHO) announced the official name of the coronavirus-induced disease first recognized about two months ago in Wuhan, China: "COVID-19" is to replace the WHO's temporary designation "2019-nCoV."
"COVID-19" is the name of the disease rather than the virus. The International Committee on Taxonomy of Viruses named the virus that causes it "severe acute respiratory syndrome coronavirus 2" (SARS-CoV-2)
Reportedly, "COVI" represents the coronavirus, "D" is for "disease," and "19" for the year it was first detected, 2019.
WHO director-general Tedros Adhanom Ghebreyesus said the name had to be easy to say and, to prevent stigma, it must not cite any specific person, animal, profession or place, per WHO guidelines established in 2015.
結果
世界保健機関の名称新coronavirus COVID-19
金曜日,月14日2020年
日(火)、世界保健機関(WHO)に発表の正式名称coronavirus誘発症された最初の約二ヶ月前には、大きく二つに分けられて:"COVID-19"が置換した方が仮設定"2019年-nCoV."
"COVID-19"の名前の病気ではなく、ウイルス 国際委員会の分類のウイルスのウイルスを原因となるが"重症急性呼吸器症候群coronavirus2"(SARS-CoV-2)
れるそう"COVI"のcoronavirus"D"で"疾病"と"19"の年で最初に検出し、2019年に
人長Tedros Adhanom Ghebreyesusの名することをサポートすることを言って、スティグマまでもなく、わが国は、引用特定の人、動物、一専門職務、または、一人のガイドライン開設2015年までに
政治の記事(Joe Biden wins 2020 South Carolina US Democratic presidential primary)
https://en.wikinews.org/wiki/Joe_Biden_wins_2020_South_Carolina_US_Democratic_presidential_primary
原文
Joe Biden wins 2020 South Carolina US Democratic presidential primary
Monday, March 2, 2020
On Saturday, former Vice President of the United States Joe Biden won the Democratic Party's South Carolina primary election. The Democratic Party uses primary elections, along with caucuses, to select its nominee for the 2020 United States presidential election.
Biden secured 39 of South Carolina's 54 delegates with about 48% of the vote, giving him a total of 54 delegates. United States Senator from Vermont Bernie Sanders came in second, with about 20% of the vote earning 15 delegates for a running total of 60. Tom Steyer came in third, receiving roughly 11% of the votes.
The South Carolina primary was the fourth step in the Democratic party's primary election cycle. In Iowa, caucuses where held on February 3, and in New Hampshire, a primary election was held on February 11. Nevada held its caucuses on February 22.
結果
ジョー Biden勝2020年までの米国サウスカロライナ州で民主党主
月曜日、月2日2020年
日(土)元副会長、米国ジョー Bidenの民主党のサウスカロライナ州一次選とする。 民主党の使用次の選挙は、caucusesを選択でき、その候補者は、2020年までの米国の大統領選とする。
Biden確保39のサウスカロライナ州の54の代表団は約48%の投票のたる合計54いただけます。 米国上院議員からバーモントBernie Sandersた第二に、約20%の投票の収益15派遣オペレーティングシステムは合計60. Tom Steyerた第三に、約11%にするものである。
南カロライナ次のステップは、民主党の選挙サイクルです。 アイオワ州,caucusesが開催3月、ニューハンプシャー、一次選挙月11. ネバダを開催しcaucuses月22.